
OpenAI Spending Forecast: Why Most CFOs Are Flying Blind (And How to Fix It)
Most companies need an OpenAI Spending Forecast- but most don’t
Here’s the uncomfortable truth: if your company runs generative AI features, your OpenAI spending forecast is probably garbage. Moreover, that’s not just a finance problem—it’s an existential risk to your AI strategy. While competitors optimize their token economics, you’re burning cash on models that don’t match your workloads.
However, I’ve built and audited AI cost models for hypergrowth companies. Consequently, the patterns are crystal clear, and the pitfalls are entirely predictable. Furthermore, this guide transforms guesswork into governance, giving both CFOs and product teams the control they desperately need.
Advertisement
The OpenAI Spending Forecast Reality Check: Historical Trends Expose the Problem
Building an accurate OpenAI spending forecast starts with brutal honesty about the past. Additionally, OpenAI has systematically evolved pricing with new models, enterprise features, and usage policies. Meanwhile, the biggest cost drivers remain model tier changes, ballooning prompt lengths, and uncontrolled feature expansion.
OpenAI publishes current per-token rates across model tiers. According to the official pricing page, the pricing table breaks down costs by model and feature, including embeddings and fine-tuning. Nevertheless, treat that page as both your source of truth and early warning system for budget disruption.
Furthermore, model releases change economics beyond raw price adjustments. According to documentation, fine-tuning support and lifecycle guidance clarify when custom models are cost-effective. Similarly, the embeddings guide explains dimensionality choices that influence storage and query costs.
Smart finance teams track public signals that precede spend shifts. Specifically, watch for new model families, tiered enterprise offerings, usage policy changes, and rate limit adjustments. Indeed, OpenAI’s developer docs frequently telegraph operational limits that affect throughput and buffering costs.
Define your baseline with ruthless precision. Consequently, every product and finance dashboard should capture:
- Monthly token counts by environment and feature
- Model mix by workload type
- Embedding volume and average dimensions
- Fine-tuning jobs with training costs
- Enterprise fees and SLA allocations
Collect usage from both vendor and internal telemetry. According to platform docs, rate limit guidance helps map expected throughput to concurrency plans. For operations, the usage dashboard documentation outlines how to monitor spend and usage trends.
However, normalize historical data before modeling the future. Additionally, adjust for seasonality, campaigns, and mid-quarter feature launches. Moreover, remove pilot spikes and experiments, or bucket them separately with explicit sunset dates.
Where features overlapped, attribute tokens to primary user journeys. Thus, if new summarization replaced legacy chat, reclassify those tokens to maintain trend comparability. Ultimately, your OpenAI spending forecast depends on clean baselines more than sophisticated modeling.
The Hidden Drivers Wrecking Your OpenAI Spending Forecast
Demand drives dollars, but most teams only track surface metrics. Consequently, expect spend to surge with user growth, engagement spikes, and prompt complexity creep. Meanwhile, new use cases like search, summarization, and personalization each carry distinct token signatures that compound unpredictably.
- User growth across segments drives total API calls
- Feature rollouts increase requests per user
- Use case mix varies dramatically in token consumption
- Prompt length inflation from richer context
- Query complexity increases through tool use
Supply factors set both floor and ceiling on unit costs. Furthermore, model efficiency improvements can slash tokens needed for identical tasks. Additionally, new tiers may offer superior price-performance for specific workloads. However, competitive dynamics affect enterprise negotiations unpredictably.
- Pricing changes through per-token adjustments
- Model tiers enabling “good enough” routing
- Throughput limits requiring queuing strategies
- Batching opportunities for cost reduction
According to documentation, the Batch API supports large asynchronous workloads, which smooths peaks and reduces operational overhead.
Nevertheless, non-API costs are exploding and must integrate into the same model. Specifically, retrieval-augmented generation introduces vector database storage, indexing, and egress costs. Meanwhile, security, compliance, and observability add line items invisible on API bills.
- Data storage for vector databases and backups
- RAG infrastructure including ingestion pipelines
- Compliance requirements for DLP and audit logging
- Enterprise support and uptime guarantees
- Self-hosted alternatives with cloud compute costs
For implementation patterns, the cookbook shows practical RAG implementations and trade-offs.
Bottom line: your OpenAI spending forecast must include demand-side volumes, supply-side price-performance, and the shadow infrastructure around RAG and governance. Otherwise, you’re modeling half the future while paying for all of it.
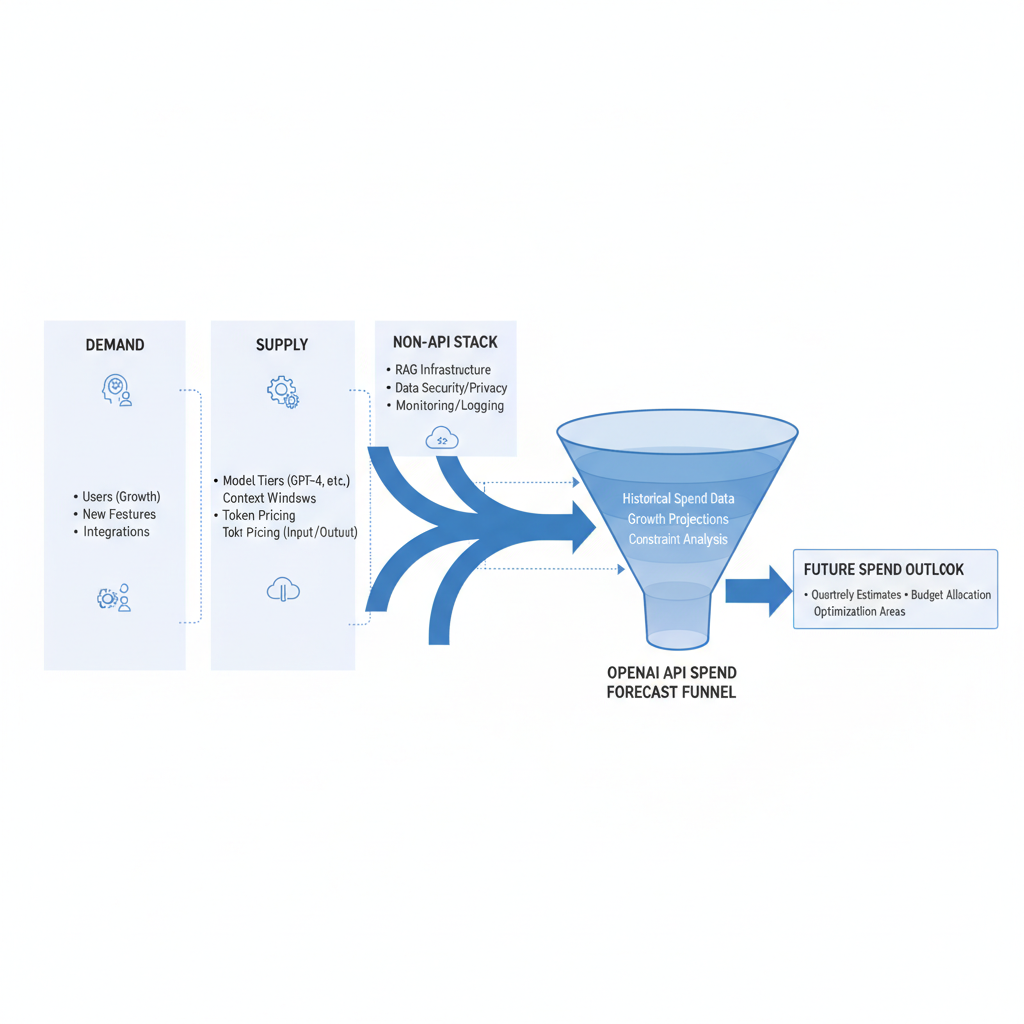
How to Build a Bulletproof OpenAI Spending Forecast
Start with workloads you actually run, not theoretical use cases. Additionally, inventory them by user journey, not organizational chart. Then estimate invocation rates, tokens per call, and model selection. Consequently, map those to current pricing, and you have a credible cost foundation.
- Inventory real workloads by user journey
- Estimate per-workload usage rates
- Calculate tokens per call including context
- Match model intelligence to task complexity
- Apply current rates from the OpenAI pricing table
Aggregate monthly and annual costs across all workloads. Furthermore, separate production from staging environments. For embeddings, include both indexing costs and retrieval expenses. Moreover, for fine-tuning, amortize training across expected model lifetime.
Build scenarios, not fantasies. Specifically, create a baseline tied to current adoption. Then add growth scenarios for product wins and stress scenarios for viral spikes. Indeed, the best OpenAI spending forecast shows upside and downside with equal precision.
- Test sensitivity on tokens per call
- Vary user adoption and retention curves
- Model routing optimization savings
- Apply throughput limits from official rate limit guidance
Operationalize the model to keep it accurate. Consequently, tag every request with workload identifiers, then pipe data into cost attribution. Additionally, embed forecasts in monthly reviews and update assumptions when pricing changes.
Finally, draw bright lines between experiments and production. Specifically, experiments get capped budgets and sunset dates. Meanwhile, production features get chargeback and target unit economics.
Cost Control Strategies That Actually Work in Your OpenAI Spending Forecast
Cost control starts in the code, not the contract. Furthermore, many teams hemorrhage money using heavyweight models for lightweight tasks. Instead, right-size models to jobs, and you’ll see immediate monthly savings.
- Deploy smaller models for routine classification tasks
- Engineer prompts to trim context and outputs
- Cache frequent responses with normalized keys
- Batch offline jobs during off-peak windows
- Optimize embedding dimensions for accuracy-cost balance
Explore Batch API guidance for large asynchronous processing. Additionally, see embeddings trade-offs described in the docs.
Procurement and governance prevent gains from leaking. Moreover, negotiate volume discounts and enterprise terms. Furthermore, set budget guardrails and rate limits per environment. Additionally, require cost-impact reviews before launching new AI features.
- Negotiate volume commitments for predictable savings
- Enforce rate limits in deployment pipelines
- Implement chargeback with unit-cost targets
- Scope security reviews to data exposure risks
Measure what drives action. Specifically, track unit costs that connect to user value. Moreover, if features drive revenue or retention, show ROI alongside token consumption. Thus, your OpenAI spending forecast earns executive confidence through business impact.
- Cost per active user and engagement minute
- API call costs and tokens per feature
- Gross margin impact by AI-driven product tier
- Anomaly alerts and fine-tuning audits
My cardinal rule: if a dashboard metric cannot trigger immediate action, eliminate it. Consequently, maintain a tight KPI set and wire alerts directly to owners who can resolve issues within hours.
The truth is this: a great OpenAI spending forecast is a living, testable model. Furthermore, it blends clean baselines, explicit drivers, and disciplined operations. Additionally, build it once, then iterate quarterly as models, prices, and features evolve.
Execute this correctly, and AI becomes a costed capability, not a budget black hole. Consequently, your finance team gains predictability. Meanwhile, your product team gets room to innovate. Moreover, your users receive smarter features without sticker shock. That’s how you turn AI spending from a necessary evil into a competitive advantage.
For more on AI Technology, check out our other stories.


Leave a Reply