
‘Anthropic CEO Hacked’ Proves Obsessing Over Model Errors Is the Dangerous Distraction
Every time someone obsesses over hallucination rates and benchmark scores, I think about when “anthropic ceo hacked” headlines could emerge. After twenty years in cybersecurity, I’ve seen billion-dollar companies destroyed. Furthermore, these failures weren’t from AI giving wonky answers. Instead, attackers exploited the weakest link—human authority.
Model accuracy matters, but context is everything. Anthropic’s Jared Kaplan told Business Insider that some errors are necessary. Perfect models would refuse to answer anything uncertain. Meanwhile, companies chase 2% accuracy improvements while ignoring a stark reality. One compromised executive account delivers exponentially more damage than any hallucination ever will.
Real-World Evidence: The Anthropic X Account Compromise
Last December’s proof came when Anthropic’s official X account got hijacked for a crypto scam. CoinMarketCap documented how attackers extracted $100,000 in minutes through a classic “rug pull.” This wasn’t model failure—it was operational security failure. However, consider this extrapolation: what if that compromised account had announced a “critical security update” to their AI model?
This fundamental misunderstanding of risk surfaces everywhere. Take the financial sector, for instance: major banks spend millions on AI bias testing. Simultaneously, they run models on infrastructure with service accounts that have God-mode permissions across their entire cloud estate.
Why ‘Anthropic CEO Hacked’ Scenarios Represent the Real AI Safety Threat
The real AI safety threat isn’t ChatGPT recommending bad restaurants. Instead, it’s someone hacking OpenAI’s infrastructure to make their models secretly recommend only restaurants paying kickbacks. The attack surface isn’t the model; it’s the human-operated systems that deploy, monitor, and control those models.
Accuracy improvements generate impressive conference talks and venture funding. Meanwhile, explaining why you spent six months implementing hardware security keys doesn’t. However, examine the actual damage patterns carefully.
Historical Precedents: When Trust Infrastructure Fails
SolarWinds affected 18,000 organizations through supply chain compromise. Additionally, 3CX infected 600,000 systems via trojanized software updates. Furthermore, Okta exposed thousands of customer credentials through session token theft. Twilio lost customer data to voice phishing attacks targeting employees.
Consider two recent spectacular failures. Scattered Spider took down MGM and Caesars with simple help desk calls. They impersonated employees to reset passwords. Similarly, Microsoft’s AI researchers accidentally exposed 38 terabytes of private data through one misconfigured Azure link.
The Nightmare Scenario: Step-by-Step Attack Progression
Envision the “anthropic ceo hacked” nightmare scenario: attackers begin with sophisticated spear phishing. They leverage leaked LinkedIn data to craft convincing emails referencing internal projects. Next, they escalate through SIM swapping the CEO’s phone number, bypassing SMS-based two-factor authentication. With control of the CEO’s digital identity, they push through an “emergency” model update that bypasses normal safety reviews.
The malicious model appears identical but contains subtle modifications. It occasionally steers financial advice toward specific investment platforms. Additionally, it recommends particular software vendors or subtly biases hiring recommendations. Since the update carries legitimate cryptographic signatures and arrives through official channels, enterprise security teams approve it automatically.
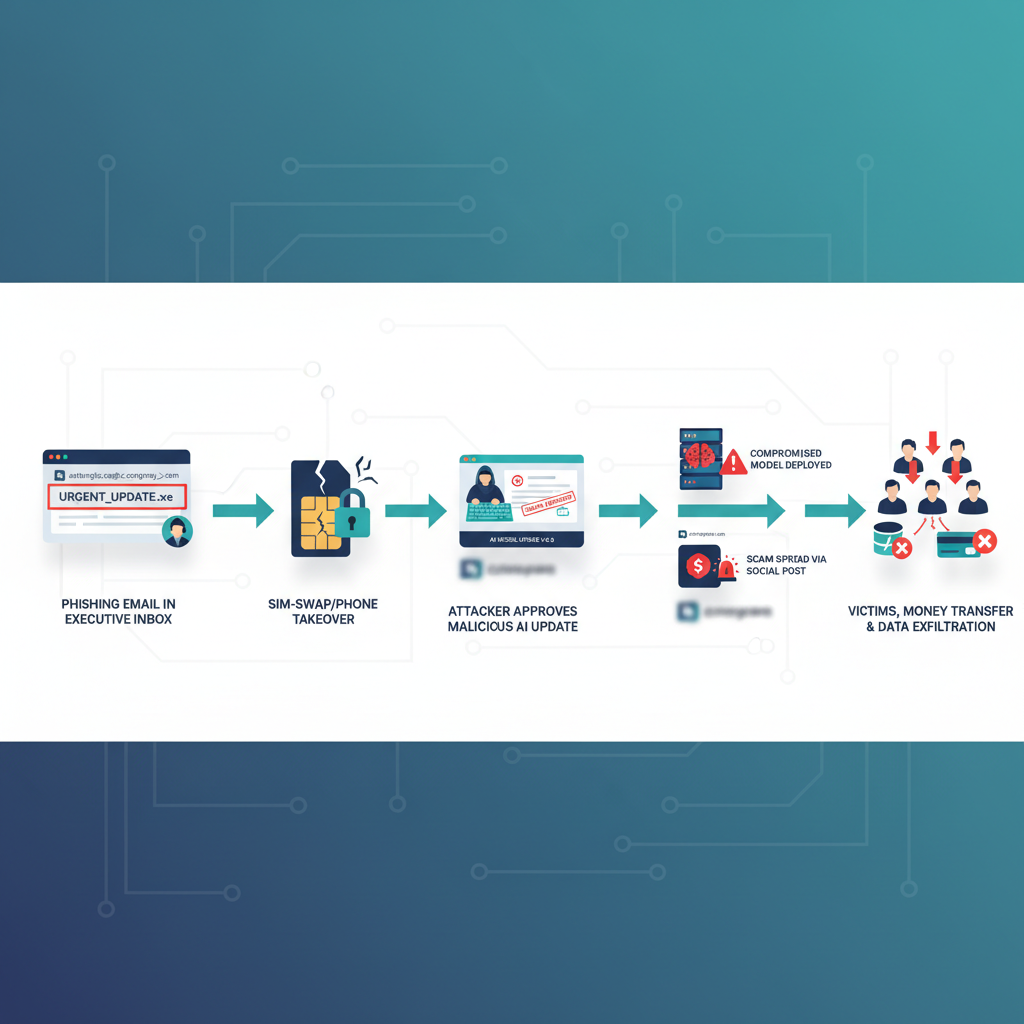
This attack requires no “jailbreaking,” no prompt injection, no defeat of safety measures. Instead, it exploits existing trust infrastructure and authority hierarchies. This is exactly why “anthropic ceo hacked” should terrify anyone serious about AI safety.
Current Security Assessment Gaps
Security assessments of AI companies reveal consistent patterns. Service accounts have excessive cross-system permissions. Models deploy without proper encryption at rest. Furthermore, executives use personal devices for authentication “convenience.”
Meanwhile, engineering teams optimize for marginally better conversational responses. The resource allocation is backwards. Operational security failures occur orders of magnitude more frequently than catastrophic model errors and typically cause more immediate, quantifiable damage.
How ‘Anthropic CEO Hacked’ Incidents Actually Unfold in Practice
Even the strongest argument for model-focused safety—preventing widespread misinformation—crumbles under operational scrutiny. History’s most damaging disinformation campaigns originated from compromised accounts and manipulated recommendation algorithms. They didn’t stem from random AI mistakes.
The mathematics of risk assessment supports this analysis. Academic research on AI alignment focuses on theoretical scenarios involving superintelligent systems. However, it ignores the demonstrable fact that current AI systems are compromised through their human-operated infrastructure dozens of times per year.
Consider three real-world examples from my consulting work. A Fortune 500 retailer discovered their recommendation AI had been subtly modified to promote specific brands. This occurred after a contractor’s laptop was compromised with commodity malware. Similarly, a healthcare system found their diagnostic AI’s training data had been poisoned when attackers gained access to their machine learning operations pipeline.
None of these incidents appeared in academic safety literature or AI ethics conferences. Despite this, each affected millions of users and caused measurable financial harm. They were resolved through operational security measures—incident response, forensic analysis, system rebuilding—not through improved model architectures.
Systematic Solutions: Zero-Trust Architecture for AI
Operational security as primary threat model requires systematic changes. For AI companies, “anthropic ceo hacked” becomes the central planning assumption. Executives must abandon SMS-based authentication for NIST-approved hardware security keys with attestation capabilities. No individual should authorize model deployments, social media posts, or infrastructure changes without cryptographically-verified multi-party approval.
Build systems following zero-trust architectural principles. Encrypt data at every tier (in transit, at rest, and in use). Additionally, verify every request against dynamic policy engines. Implement principle of least privilege with just-in-time access controls.
Use cryptographic signing with transparency logs for all model artifacts. This ensures tamper detection and non-repudiation. Follow Supply Chain Levels for Software Artifacts (SLSA) frameworks. These implement build provenance and prevent unauthorized code injection.
Deploy monitoring that detects human-targeted attacks rather than just model misbehavior. Alert on executives accessing systems from new geographic locations. Furthermore, monitor attempts to circumvent approval workflows or statistical shifts in model output distributions. Implement honeypot accounts and channels that trigger immediate incident response when accessed.
Establish operational security key performance indicators with executive accountability. Track hardware security key adoption rates across privileged accounts. Additionally, monitor credential revocation speed during incident response. Link executive compensation to these metrics alongside traditional business outcomes.
Implementation Guidelines by Stakeholder
For regulators and policymakers, expand AI safety frameworks beyond model behavior to include operational assurance. CISA’s secure-by-design guidance should explicitly cover AI systems. It should mandate cryptographic integrity for training data. Reference frameworks like the OWASP Top 10 for LLM Applications while recognizing that prompt injection defenses are insufficient without underlying infrastructure security.
Critics argue this approach imposes excessive costs or inhibits innovation velocity. This reflects backwards thinking. Organizations with robust security practices deploy faster because they avoid the devastating interruptions of breach response and system rebuilding.
Others worry that de-emphasizing model error reduction accepts subtle, widespread harm from AI mistakes. This concern misunderstands the risk timeline. Over the next several years, “anthropic ceo hacked” style incidents are both more probable and more immediately devastating than marginal improvements in hallucination rates would prevent.
Consider the Equifax breach’s downstream effects: 147 million Americans’ personal data exposed, years of identity theft, billions in remediation costs, and permanent erosion of consumer trust. Now imagine similar organizational failure at a major AI company. Instead of exposing historical credit data, attackers gain persistent access to systems that influence millions of daily decisions.
Targeted Recommendations for Key Stakeholders
For researchers, redirect portions of safety funding toward operational guarantees. Focus on cryptographic proofs that training data hasn’t been tampered with. Additionally, develop verifiable methods to ensure deployed model weights match intended configurations. These challenges require serious cryptographic innovation—secure multi-party computation for federated learning, zero-knowledge proofs for model integrity verification.
For Chief Information Security Officers, conduct regular tabletop exercises simulating executive account compromise. Map every system your CEO can access, every approval they can authorize, every communication channel they control. Design containment procedures that don’t depend on that same compromised executive being available to assist.
For policymakers, redefine “AI safety” to encompass identity assurance, secure development lifecycles, and post-quantum cryptographic readiness. Fund independent red team assessments that include social engineering specialists and supply chain security experts alongside traditional ML security researchers. Recognize that AI systems operate within broader sociotechnical systems where human factors dominate risk profiles.
Redefining AI Safety Priorities: From Model Perfection to Operational Reality
The goal isn’t ignoring model accuracy but establishing appropriate priorities. As Kaplan noted to Business Insider, perfect accuracy isn’t desirable because it reduces model utility. However, examining how genuine harm manifests—through financial theft, system manipulation, trust exploitation—operational security failures dominate every meaningful metric.
The phrase “anthropic ceo hacked” encapsulates cybersecurity’s fundamental truth. Attackers consistently choose the shortest path through human psychology and institutional trust. They avoid the longest path through mathematical complexity and algorithmic sophistication.
Reorienting this debate means recognizing teams building robust operational security with the same prominence as teams optimizing model performance metrics. When someone argues that AI safety exists entirely within model weights, recall that X account compromise. Remember SolarWinds’ supply chain infiltration. Remember that every CEO is perpetually one convincing social engineering attack away from authorizing something catastrophic.
The public deserves AI systems that remain safe in the chaotic, human-operated world where real attackers operate. These systems shouldn’t only work in laboratory conditions optimized for academic evaluation. Positioning “anthropic ceo hacked” as the primary threat model and building all other security measures from that foundation addresses the actual risk landscape.
The measurable harm we’re trying to prevent won’t register in any benchmark or safety evaluation. Discovering it through tomorrow’s headlines means the failure occurred months or years too late to matter.
For more on AI & Technology, check out our other stories.







